Review Experience
Confidence Scores
Extend uses machine learning models to extract information from documents. A confidence score tells you how ‘confident’ the model is about the accuracy of an extracted value. The score is presented as a number between 0 and 1, with values closer to 1 indicating higher confidence.
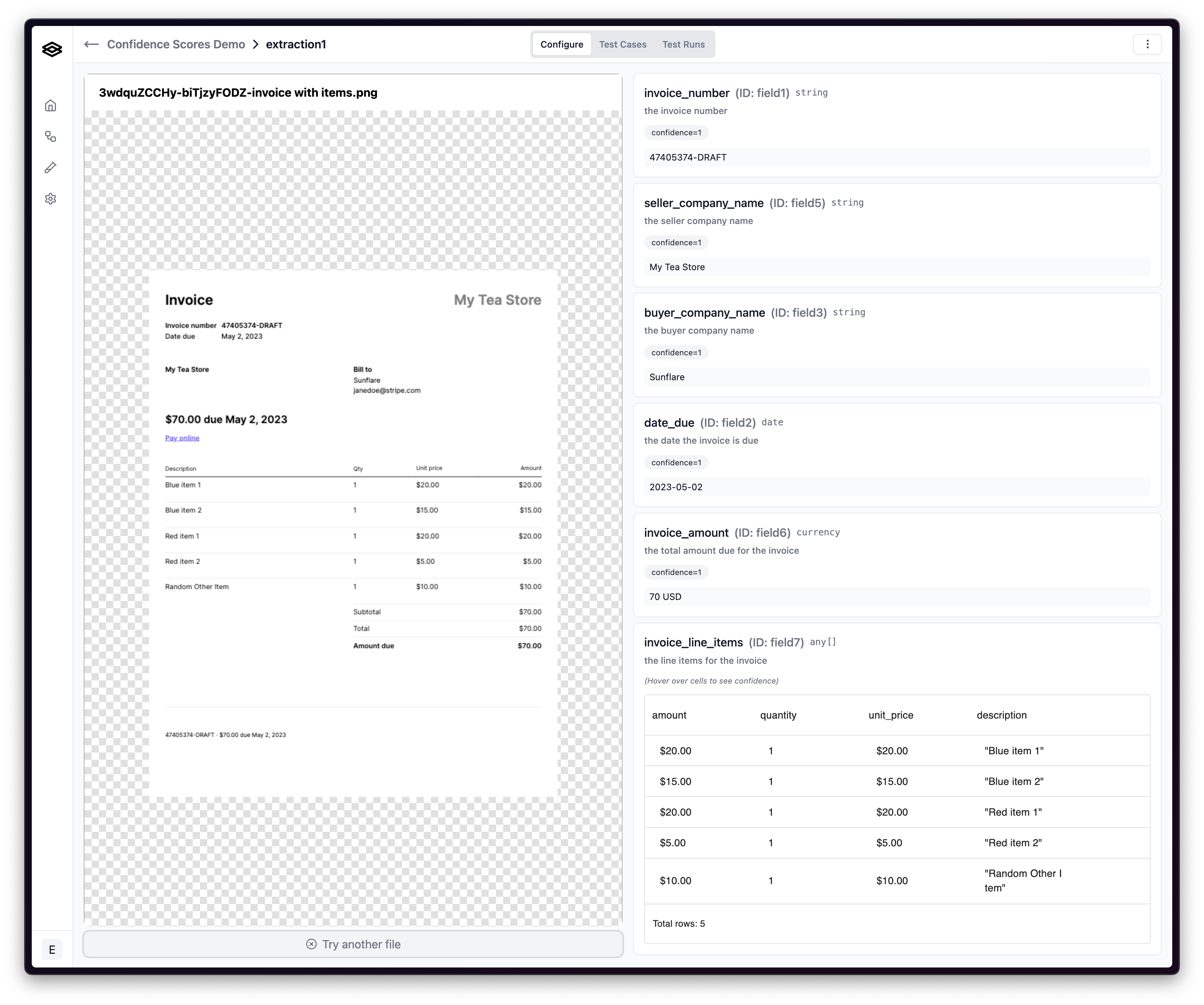
Below, you can see an example of an extraction with high confidence, and that all of the extracted values are correct.
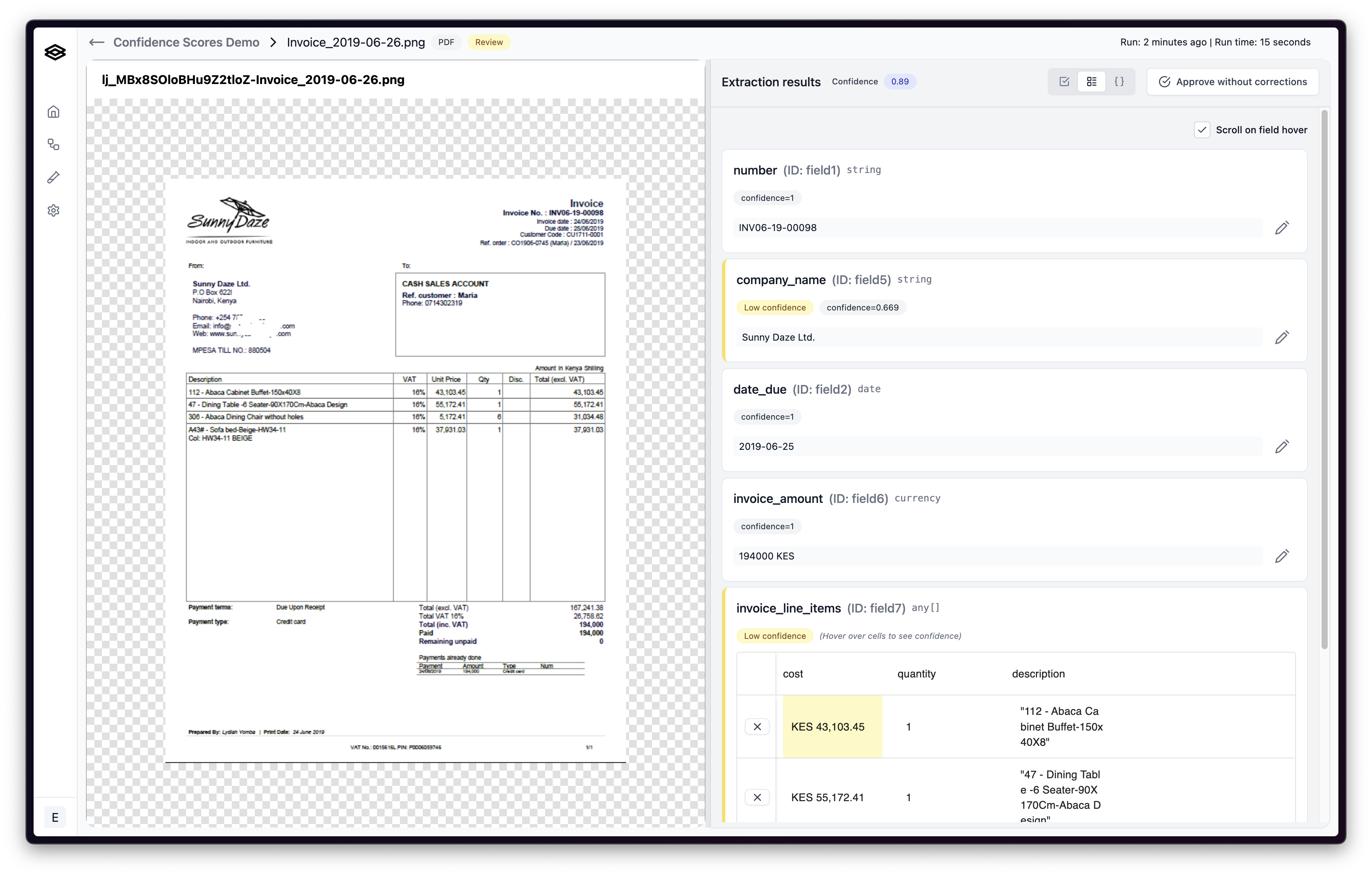
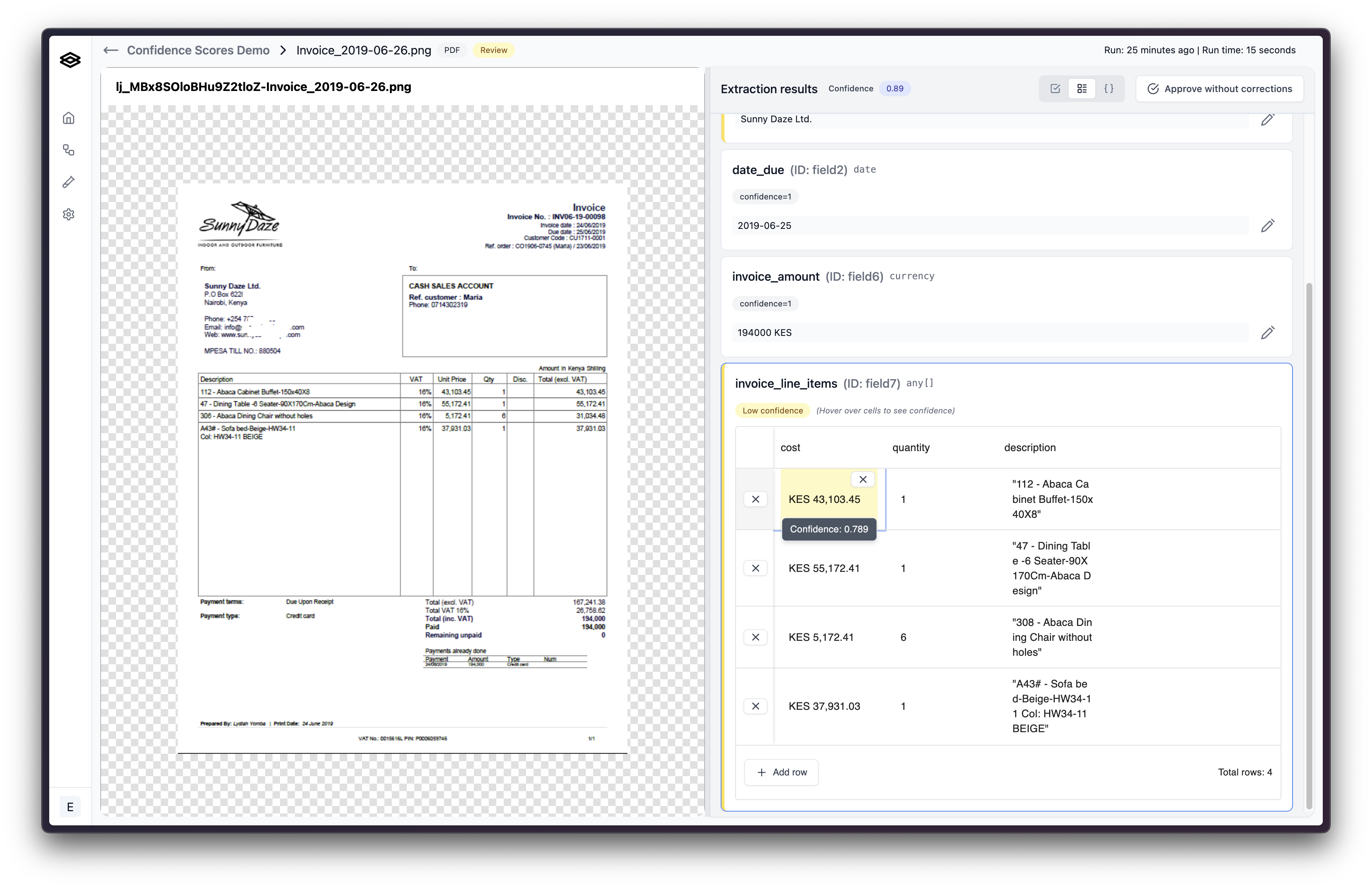 Low confidence values are highlighted yellow. When reviewing an array with highlighted low confidence values.
Low confidence values in arrays might indicate that the model doesn’t have enough context to extract the value correctly or that the model is confused by the format of the document. In these cases, it may be helpful to add more context to your extraction field descriptions. If this does not remedy the issue, reach out to the Extend team.
Low confidence values are highlighted yellow. When reviewing an array with highlighted low confidence values.
Low confidence values in arrays might indicate that the model doesn’t have enough context to extract the value correctly or that the model is confused by the format of the document. In these cases, it may be helpful to add more context to your extraction field descriptions. If this does not remedy the issue, reach out to the Extend team.
How do I use Confidence Scores?
Here’s how you can incorporate confidence scores into your workflow:Using Conditionals
Using conditional steps, you can handle a document differently depending on whether it’s extraction confidence score is above or below a certain ‘confidence threshold’. For instance, if you’re extracting important financial data, you might set a high threshold, accepting only data with confidence scores above 0.95. For less critical data, a lower threshold might be acceptable.
Review and Verification
Use confidence scores to prioritize data for review. Data points with low confidence scores might need manual verification or further investigation.Data Filtering
In large datasets, you may want to filter out data below a certain confidence level to ensure the quality and reliability of your analysis.Limitations of Confidence Scores
While confidence scores are a valuable tool in assessing the reliability of extracted data, it’s important to recognize their limitations to use them effectively. Here are some key points to consider:Not a Guarantee of Accuracy
A high confidence score indicates a high probability of correctness, but it doesn’t guarantee accuracy. Even with a high score, there’s always a chance of errors, so critical data should always be cross-verified.Context Matters
Confidence scores are calculated using models and their understanding of the data. They may not account for nuances or context that a human reviewer who understands your business would recognize. Because of this, it’s imperative to supply sufficient context on the value you want extracted so the AI can determine whether it is confident or not. For example, if you name a field “company_name” on an extractor designed for invoices, the model may not be confident on which name you are asking for as there are a couple different company names on invoices.
Confidence in Arrays
Arrays are one of the data types that can be extracted from a document. They are a collection of values that are related to each other. For example, a table of line items on an invoice could be extracted as an array. Confidence scores for arrays should be treated differently than confidence scores for other data types. For arrays, a confidence score is calculated for each individual value in the array. To view these confidences, hover over the cell the value is contained in.
Low confidence values are highlighted yellow. When reviewing an array with highlighted low confidence values.
It is important to check the values around the low confidence value to make sure they are correct in addition to the flagged value.